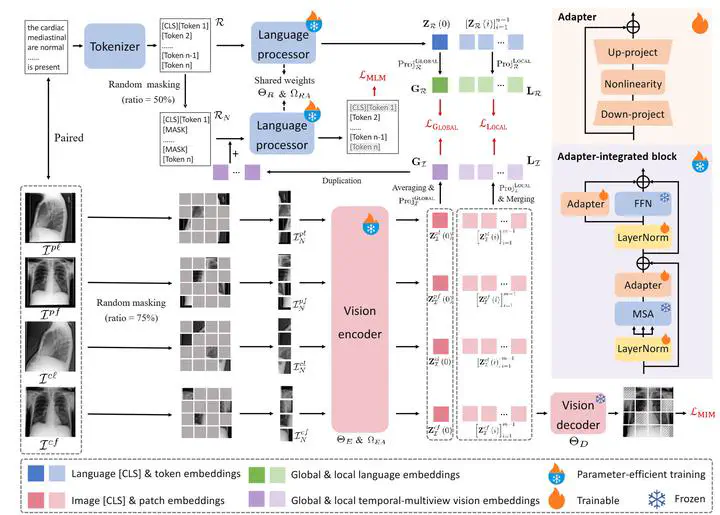
Abstract
Medical vision-language alignment through cross-modal contrastive learning shows promising performance in image-text matching tasks, such as retrieval and zero-shot classification. However, conventional CLIP-based methods suffer from suboptimal visual representation capabilities, which limits their effectiveness in vision-language alignment. In contrast, models pretrained via multimodal masked modeling struggle with direct cross-modal matching but excel in visual representation. To address this contradiction, we propose ALTA (ALign Through Adapting), an efficient medical vision-language alignment method that adapts a pretrained vision model from masked record modeling while using only about 8% of the trainable parameters and less than one fifth of the computational consumption required for masked record modeling. ALTA achieves superior performance in retrieval and zero-shot classification, and integrates temporal-multiview radiograph inputs to improve the consistency between radiographs and report descriptions. Experiments show that ALTA outperforms the best-performing counterpart by over 4% absolute points in text-to-image accuracy and approximately 6% absolute points in image-to-text retrieval accuracy.